TLDR: The code was using a suboptimal data layout,
Links:
The software at work processes files containing signal values. The size of these files can vary wildly - I've seen files consisting of a few kilobytes, and I've seen some which take up several gigabytes.
We are working in C++, so for small signals, we simply store them
using std::vector<float> [0].
In case you aren't familiar with C++: You can think of std::vector
as a resizable array.
The software might apply some additional processing / conversions,
so we just create a new std::vector<float>.
All the resizing and managing memory is handled by std::vector,
such that we don't need to worry about it.

For small signals, everything is fine. Displaying them just entails iterating over the array, using some knowledge about which range of indices are visible and relevant for the user.
However, these signals can get large [1]. So large in fact, that displaying them quickly is kind of difficult: Even if you know start/end indices, the sheer amount of values is completely overkill for displaying, making you skip over most values holding the rest in memory for no good reason.
The authors of the file format came up with some signal reduction data. Basically using some resolution factor, you can get a "pre-processed" signal, where each entry contains
One of these entries maps to a lot of the "raw" signal values, such that the signal reduction data can be used for displaying (unless you are super zoomed in).
The code I was looking at decided to store this signal
reduction data as std::vector<std::vector<float>>:

Not pretty, but it works I guess. However, there's two problems with this approach:
First, we do additional processing on the signal. The existing code is
std::vector<float> of the
mean/min/max valuesstd::vector<std::vector<float>>
These conversions are obviously a complete waste of time; we
can just store three std::vector<float> and save us
all of the conversion code.
However, even if we don't do any conversions,
accessing all the values of std::vector<std::vector<float>> comes
with harsh performance penalties (when comparing to std::vector<float>).
This makes the conversion functions even worse.
To skip ahead, I switched the representation as follows:
// From
std::vector<std::vector<float>>
// To
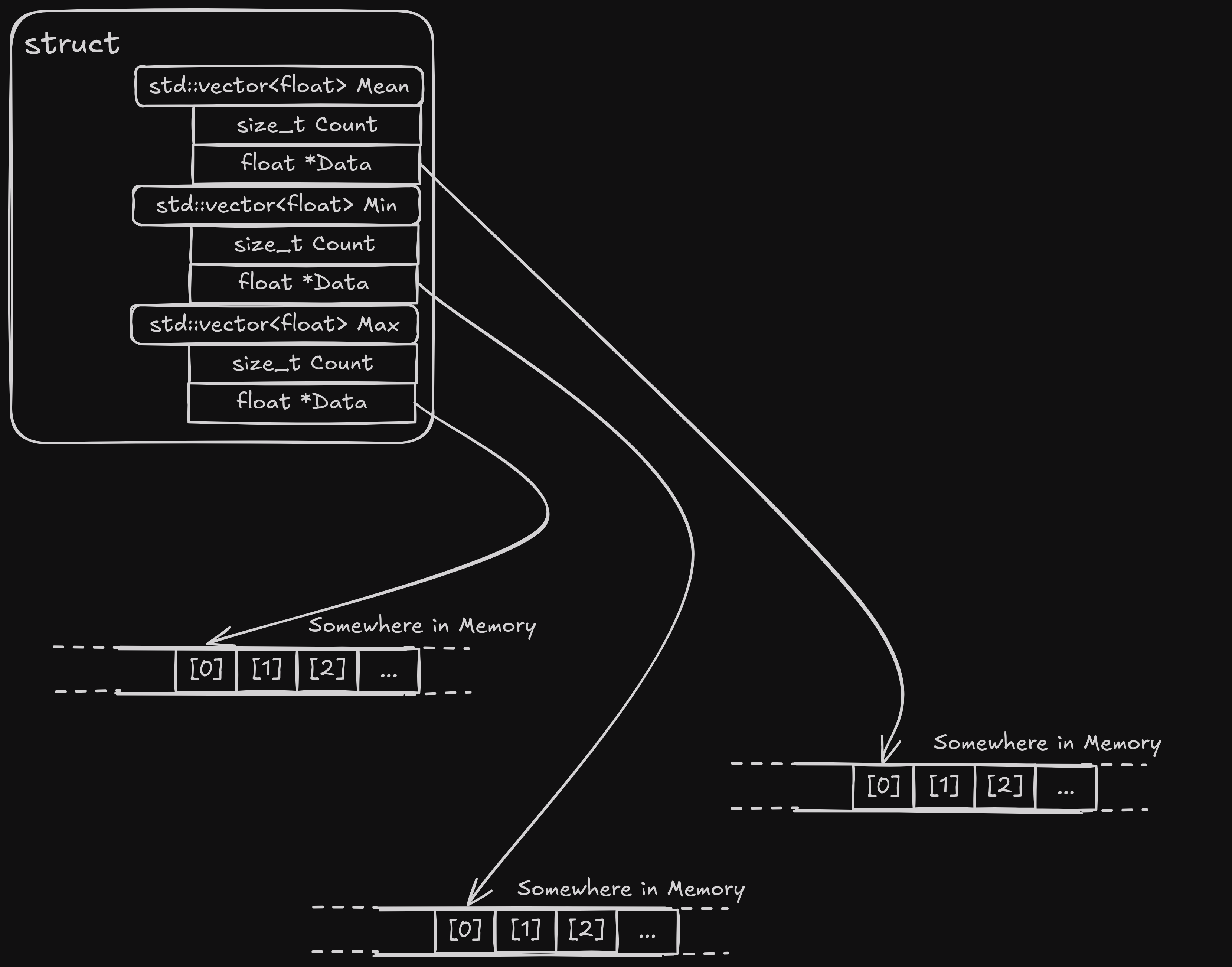
struct sample_reduction_data
{
std::vector<float> mean;
std::vector<float> min;
std::vector<float> max;
};This resulted in a speedup of >20x. For non-trivial files, we are talking reducing the loading times from 1.2s to 0.06s. That's absolutely insane! Think of how many generations of hardware it takes to give you a speedup of 20x. And it resulted in less code because the conversion functions are gone.
So, what do I mean with performance penalties?
First, we need to understand, very roughly,
how std::vector works.
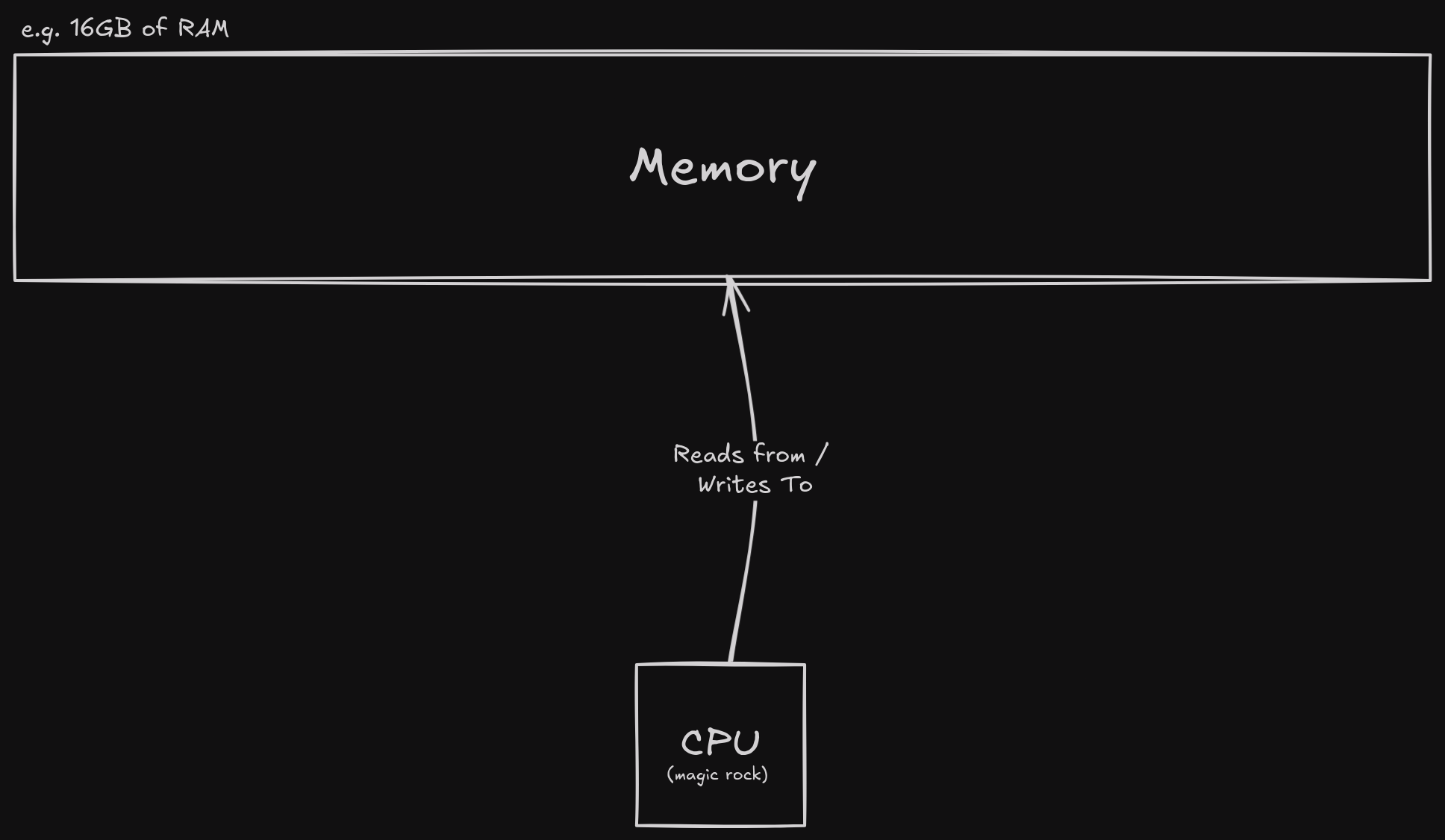
std::vector handles all the memory allocations / re-allocations / deallocations.
You can easily hold gigabytes of data using an std::vector you placed on the stack,
without crashing your program.
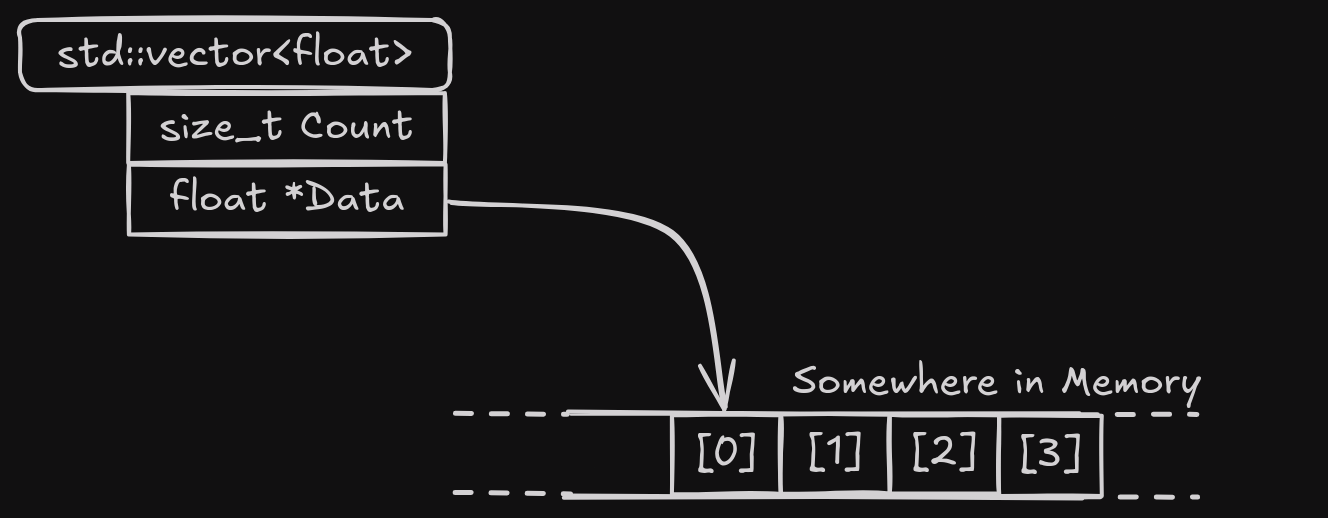
This is because the actual elements of std::vector aren't allocated on the stack.
The elements are stored somewhere on the heap,
which I like to imagine like this:
Second of all, the memory setup of modern desktops is pretty important. During university, most of the time, this is just some irrelevant implementation detail. For the most part, Computer Science is about the science of computing stuff, and not really computers themselves.
But we are dealing with actual hardware now, and the performance penalty comes from wasting the CPU cache. CPUs are extremely fast. So fast in fact, that requesting memory from your RAM is utterly dogshit slow. So hardware designers decided to use several levels of CPU caches [2]:
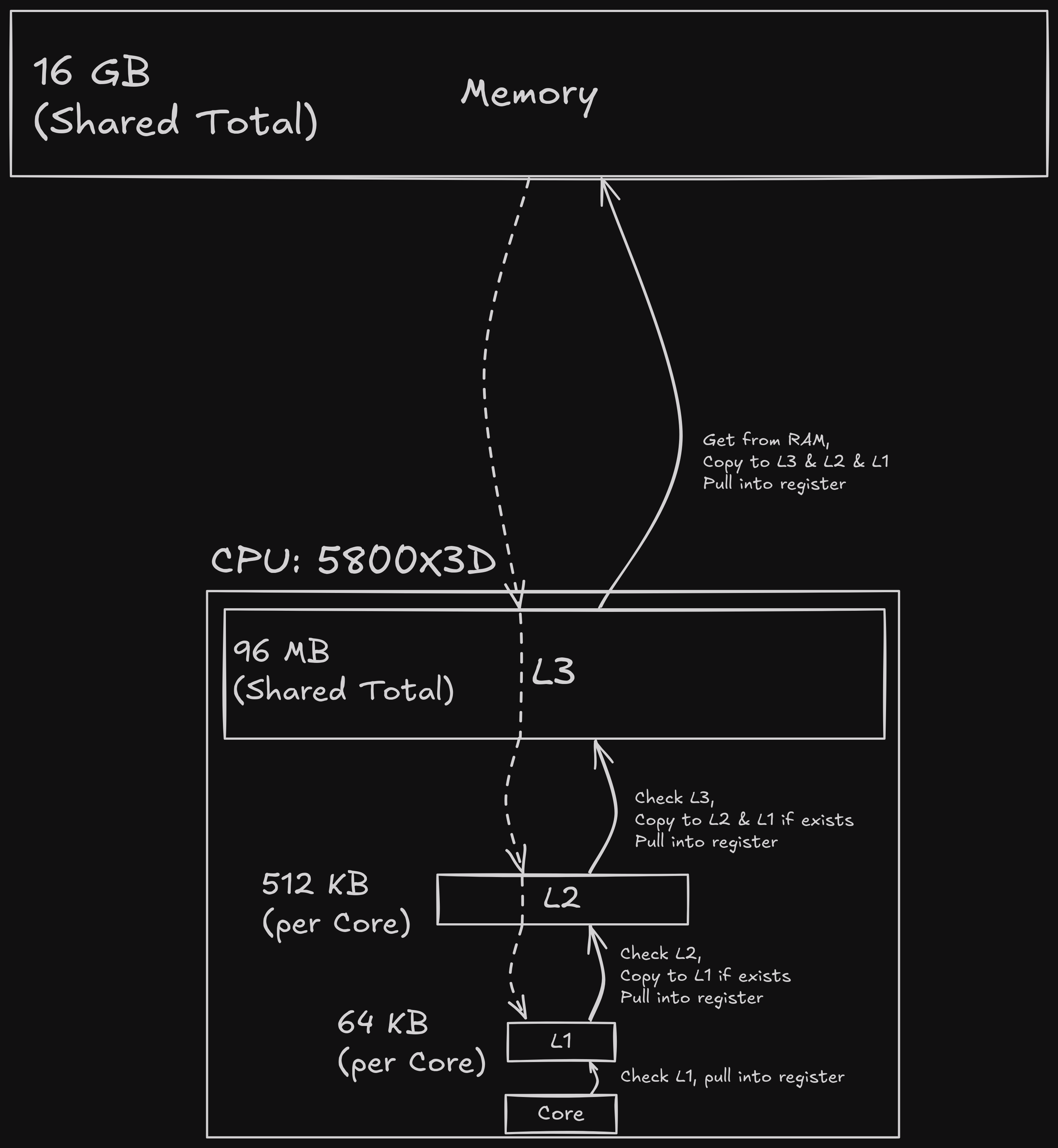
So whenever you need some bytes (which are not in a CPU register), your CPU
If it finds the bytes you are looking for, it brings the bytes into all caches, replacing older stuff [4].
Now that you know all of this, we can talk about the actual reason why the data format was bad: Cache lines.
You might imagine that your CPU queries individual bytes, e.g. four bytes when trying to access a float in memory:

That is incorrect for most desktop CPUs.
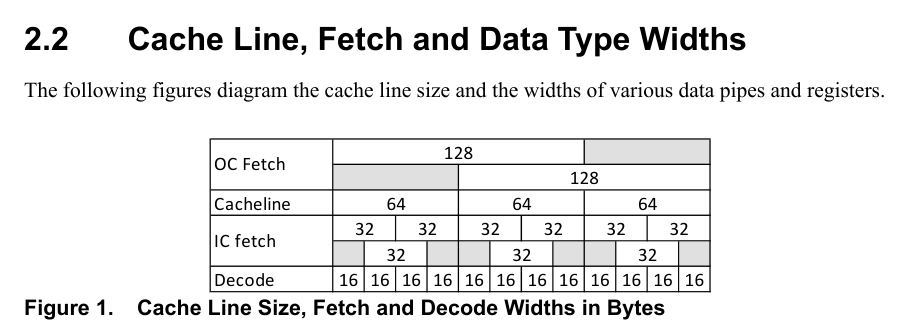
Your CPU requests memory bytes in form of cache lines.
Each cache line consists of 64 bytes, so even if you
query just a single uint8_t, if the cache line isn't
in your cache, you are pulling in 64 bytes at a time [5].
If you are really interested, you should check the documentation from your CPU vendor. For example for AMD, you can look this stuff up in the AMD Documentation Hub:
So when you access the single float, it will fall into some cache line:

When thinking about performance, you have to keep these cache lines in mind.
As I said for small signals, we use a single std::vector<float>.
When processing all values, the CPU will (roughly) work like this:
First, we start with the first value. It's likely not in the cache, so that's a cache miss, meaning we need to fetch the cache line.
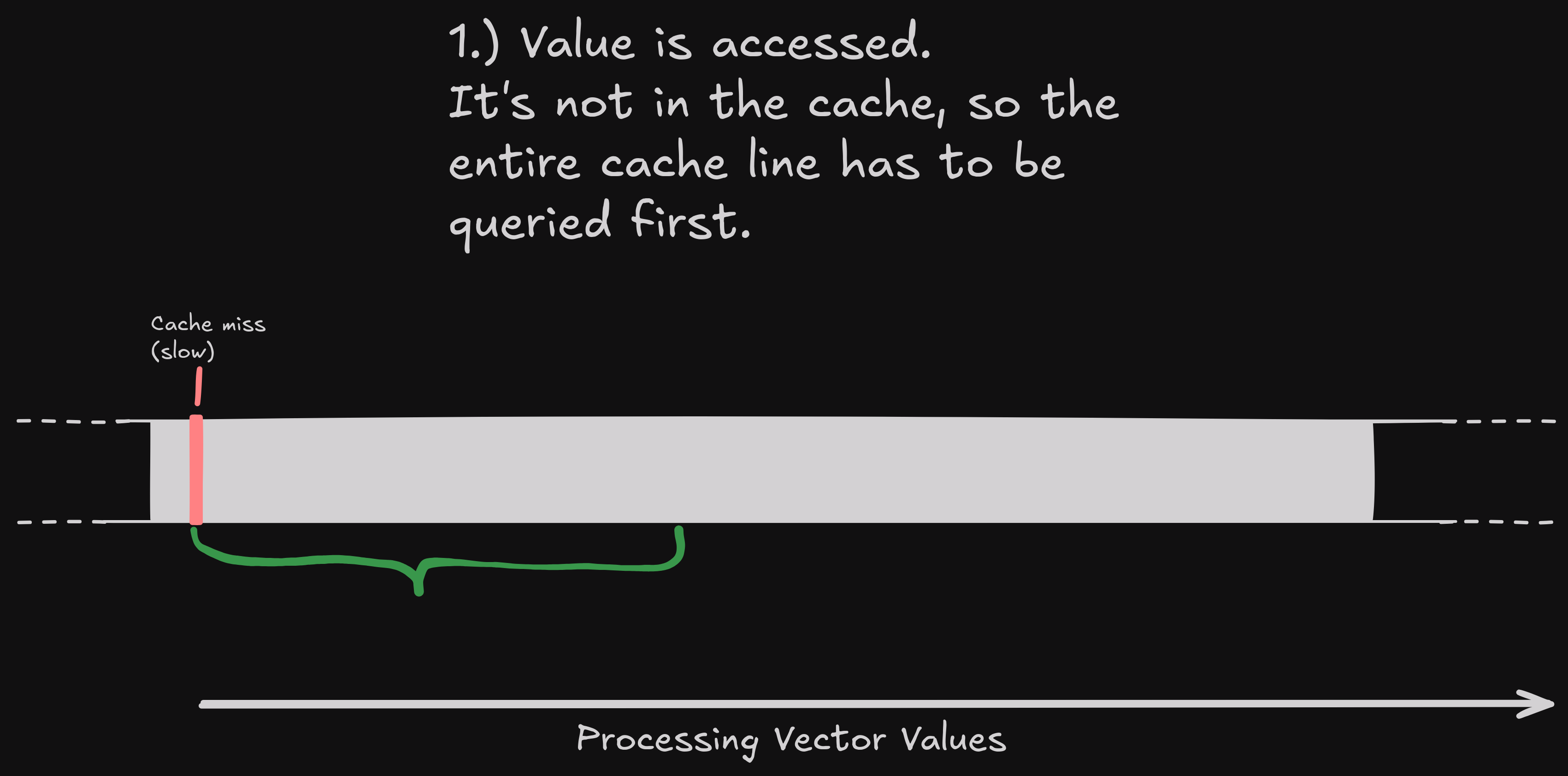
Now we process the second value of the std::vector<float> elements.
As the elements are right next to another, these two elements
will (likely) share the same cache line.
As we just fetched the same cache line, the value is in our cache,
so accessing this element is super fast now.

A cache line is 64 bytes. A single float is 4 bytes. If we process the elements in order in quick succession, we will get:

And obviously, this process repeats once we reach the next cache line:
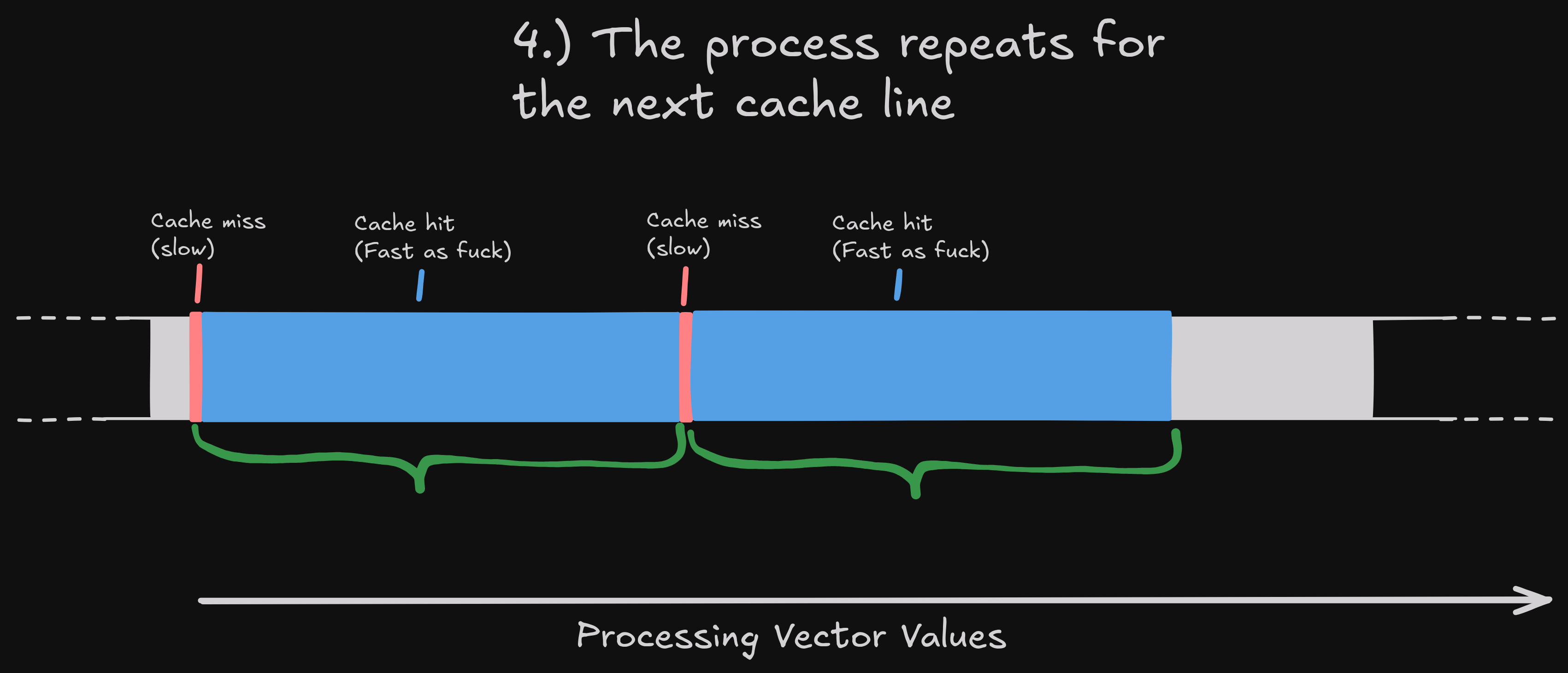
You might already now understand why a flat std::vector<float> is
preferrable when processing lots of values, but I'll go over
it anyway.
To recall, the original code used a std::vector<std::vector<float>>,
which stores elements in groups of three:
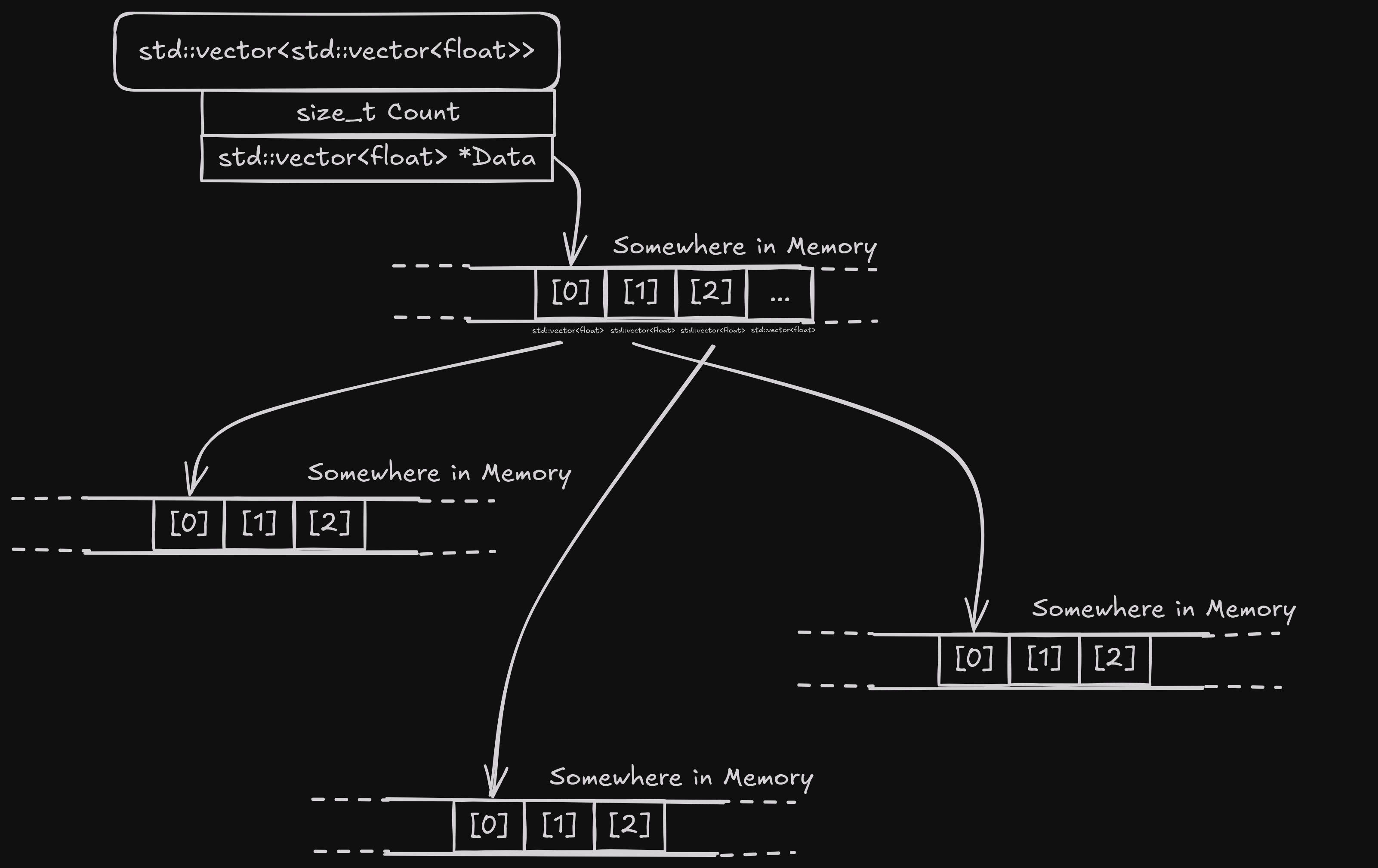
So when we process all elements, we are wasting most of our cache line:
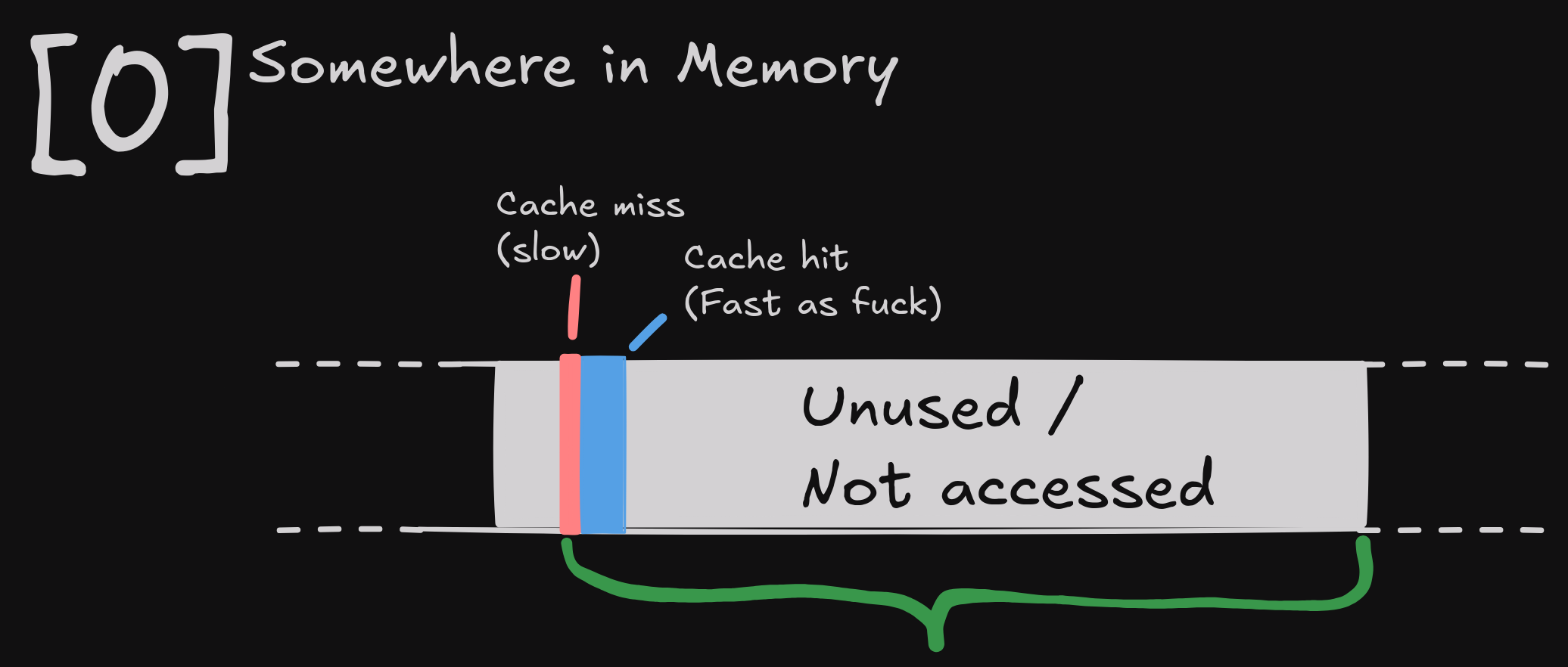
The process repeats, as the next three elements are probably somewhere else entirely.
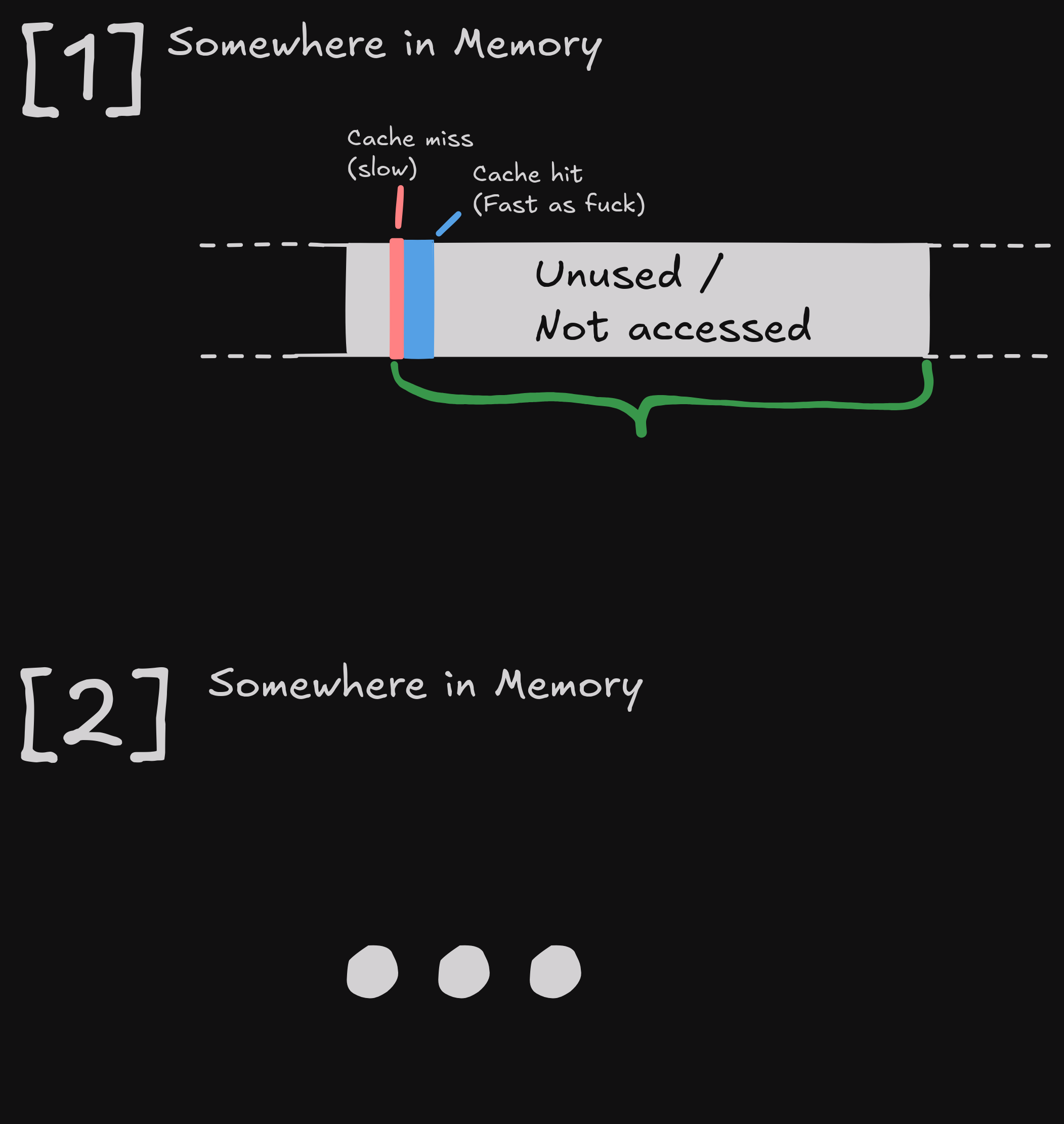
A float is 4 Bytes, so using three floats of a cache line leaves us with an
cache line utilization of 3*4 / 64 = 0.1865 => 18.75%.
Ouch!
Let's compare this to the "three seperate std::vector<float>"-approach.
In memory, it will look something like this:
So when processing all elements, this is our cache line utilization:

No wonder the performance is much better with this approach. Caches are a huge deal when it comes to performance. And here, these "optimizations" [6] stack on top of another: The better cache lines speed stuff up a lot, and you can multiply the performance boost with the reduced amount of computational waste due to the conversions.
Once again: This was a >20x performance improvement, while
using less code!
And I'd even argue the code is more readable, given that
std::vector<std::vector<float>> doesn't tell you much
about the sizes of the nested std::vector<float>.
I didn't apply any fancy algorithms, I just shuffled some things in memory. Same "O(n)" stuff. This is why I like to learn stuff about computers. Treating everything as a magical blackbox/abstraction can very quickly lead to wasted performance.
I'll probably port a short explanation of CPU Cache lines to the HowTheFucc website, but for the time being, this is my write up of this interesting incident at work.
[0]: I'm not a fan of the C++ STL, but std::vector
is one of the reasonable containers.
[1]: This is not about us discovering myVector.reserve(...).
That was already used when working with such data.
[2]: I'm refraining from using specific cpu cycle counts. I don't have the specific numbers as hardware changes with each generation. The gist of it stays the same though.
[3]: Technically it can also use your storage drives, but that's not relevant here.
[4]: Cache eviction strategies are also worth reading about! The behavior can be relevant in some circumstances.
[5]: You might even query multiple cache lines at once! If your memory is not aligned properly and if you e.g. query a double, consisting of 8 bytes, it can range over two cache lines. Though usually when you allocate memory, this shouldn't happen for any of the primitives.
[6]: I like the idea of ComputerEnhance, where this is called "non-pessimization". I haven't spend a lot of time optimizing. This is just understanding what is performing, and taking a representation which is not completely awful. Just be "Performance Aware".